
관련 논문: “LightNVM: The Linux Open-Channel SSD Subsystem”
pblk: Physical Block Device Target
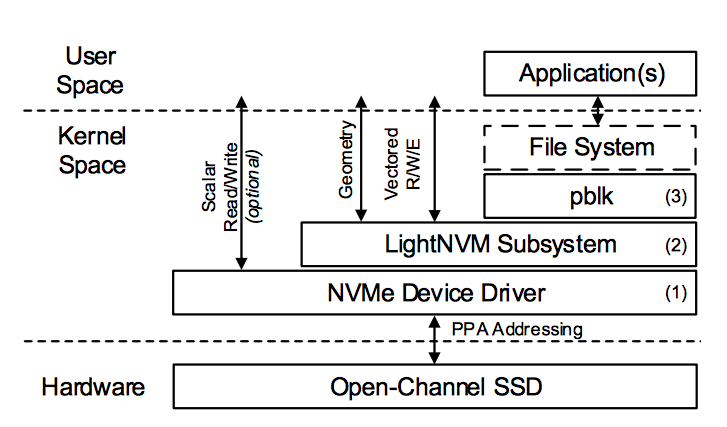
pblk implements a fully associative, host-based FTL that exposes a traditional block I/O interface. Its primary responsibilities are:
- Map logical addresses onto physical addresses (4KB granularity) in a logical-to-physical (L2P) table.
- Maintain the integrity and consistency of the L2P table as well as its recovery from normal tear down and power outage.
- Deal with controller- and media-specific constrains.
- Handle I/O errors.
- Implement garbage collection.
- Maintain consistency across the I/O stack during synchronization points.
For more information please refer to: http://lightnvm.io
Source Code Overview
LightNVM와 관련된 중요한 기능의 대부분은 커널 소스코드의 /driver/lightnvm/에 구현되어 있으며 각 file별 주요 구현 내용은 다음과 같다.
nvme block device의 creation은 core.c 파일에 구현되어 있다. write buffering, address mapping, garbage collection과 같은 기존의 FTL에서 수행하고 있던 기능들은 pblk-* file에 구현되어 있다.
- pblk.h - Implementation of a Physical Block-device target for Open-channel SSDs.
- rrpc.h, rrpc.c - Implementation of a Round-robin page-based Hybrid FTL for Open-channel SSDs.
- pblk-cache.c - pblk’s write cache
- pblk-core.c - pblk’s core functionality
- pblk-gc.c - pblk’s garbage collector
- pblk-init.c - pblk’s initialization.
- pblk-map.c - pblk’s lba-ppa mapping strategy
- pblk-rb.c - pblk’s write buffer
- pblk-read.c - pblk’s read path
- pblk-recovery.c - pblk’s recovery path
- pblk-rl.c - pblk’s rate limiter for user I/O
- pblk-sysfs.c - pblk’s sysfs
- pblk-write.c - pblk’s write path from write buffer to media
Overview of read path (This is a work in progress.)
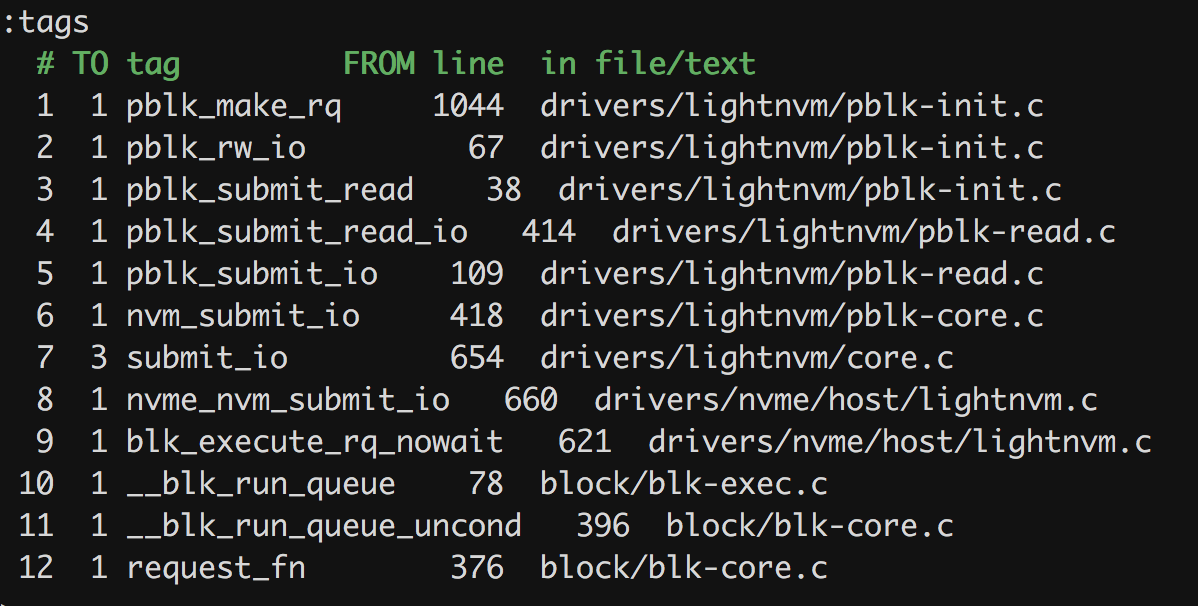
파일 시스템으로부터의 I/O는 make_rq와 mapping 된 pblk_make_rq함수에 의해 수행된다.
static blk_qc_t pblk_make_rq(struct request_queue *q, struct bio *bio)
{
.
.
switch (pblk_rw_io(q, pblk, bio)) {
.
.
}
}
static int pblk_rw_io(struct request_queue *q, struct pblk *pblk, struct bio *bio){
if (bio_data_dir(bio) == READ) {
. . .
ret = pblk_submit_read(pblk, bio);
. . .
return ret;
}
//else -> write
.
.
}
pblk_rw_io에서 read i/o일 경우 pblk_submit_read함수 호출
int pblk_submit_read(struct pblk *pblk, struct bio *bio){
.
.
// rqd는 nvm_rq structure 타입의 변수로서,
// bio structure, ppa address 등을 멤버 변수로 갖는다.
// 본 함수 내에서 bio, ppa를 포함한 rqd를 완성하여
// submit 함.
rqd structure forming
// lba to ppa translation
if(nr_secs>1){
. . .
pblk_read_ppalist_rq(pblk, rqd, blba, &read_bitmap);
}
else
pblk_read_rq(pblk, rqd, blba, &read_bitmap);
.
.
ret = pblk_submit_read_io(pblk, rqd);
}
pblk_read_ppalist_rq(pblk, rqd, blba, &read_bitmap){
//pblk_read_rq(pblk, rqd, blba, &read_bitmap) 함수 공통
.
.
//blba to ppa translation
pblk_lookup_l2p_seq(pblk, &ppa, lba, 1);
.
.
// 만약 캐시에 있으면 캐시에서 읽는다.
// 여기서 캐시는 write buffer를 말함.
if (pblk_addr_in_cache(ppa))
{
if(!pblk_read_from_cache(pblk, bio, lba, ppa, 0, 1)) {
pblk_lookup_l2p_seq(pblk, &ppa, lba, 1);
goto retry;
}
}
else
rqd->ppa_addr = ppa;
.
.
}
pblk_trans_map_get 함수를 통해 address translation을 수행한다. 이때 mapping table 에 access는 spin lock에 의해 sychronize 된다.
Todo: mapping table에 누가 또 access하는지 찾아보자.
void pblk_lookup_l2p_seq(struct pblk *pblk, struct ppa_addr *ppas, u64 *lba_list, int nr_secs)
{
.
.
spin_lock(&pblk->trans_lock);
for (i = 0; i < nr_secs; i++) {
lba = lba_list[i];
.
.
ppas[i] = pblk_trans_map_get(pblk, lba);
}
spin_unlock(&pblk->trans_lock);
}
pblk structure에서 trans_map이라는 자료구조를 통해 translation mapping table을 관리하고 있으며, 본 함수를 통해 logical block address를 physical page address로 변환한다.
static inline struct ppa_addr pblk_trans_map_get(struct pblk *pblk, sector_t lba)
{
struct ppa_addr ppa;
if (pblk->ppaf_bitsize < 32) {
u32 *map = (u32 *)pblk->trans_map;
ppa = pblk_ppa32_to_ppa64(pblk, map[lba]);
} else {
struct ppa_addr *map = (struct ppa_addr *)pblk->trans_map;
ppa = map[lba];
}
return ppa;
}
static int pblk_submit_read_io(struct pblk *pblk, struct nvm_rq *rqd){
..
err = pblk_submit_io(pblk, rqd);
..
}
rqd->nr_ppas 만큼 bad ppa 검사, 이때 spin lock으로 synchronization구현.
int pblk_submit_io(struct pblk *pblk, struct nvm_rq *rqd)
{
.
.
for(i=0; i< rqd->nr_ppas; i++){
spin_lock(&line->lock);
//pad ppa 검사
spin_unlock(&line->unlock)
}
.
.
return nvm_submit_io(dev, rqd);
}
int nvm_submit_io(struct nvm_tgt_dev *tgt_dev, struct nvm_rq *rqd)
{
.
.
ret = dev->ops->submit_io(dev, rqd);
if(ret)
nvm_rq_dev_to_tgt(tgt_dev_rqd);
return ret;
}
submit_io는 nvme_nvm_submit_io로 매핑되어 있다.
static int nvme_nvm_submit_io(struct nvm_dev *dev, struct nvm_rq *rqd)
{
.
.
blk_execute_rq_nowait(q, NULL, rq, 0, nvme_nvm_end_io);
}
request queue에 I/O를 집어넣는다. 비 동기적으로 실행된다. request queue access시 spin lock.
/**
* blk_execute_rq_nowait - insert a request into queue for execution
* @q: queue to insert the request in
* @bd_disk: matching gendisk
* @rq: request to insert
* @at_head: insert request at head or tail of queue
* @done: I/O completion handler
*
* Description:
* Insert a fully prepared request at the back of the I/O scheduler queue
* for execution. Don't wait for completion.
*
* Note:
* This function will invoke @done directly if the queue is dead.
*/
void blk_execute_rq_nowait(struct request_queue *q, struct gendisk *bd_disk, struct request *rq, int at_head, rq_end_io_fn *done)
{
int where = at_head ? ELEVATOR_INSERT_FRONT : ELEVATOR_INSERT_BACK;
WARN_ON(irqs_disabled());
WARN_ON(!blk_rq_is_passthrough(rq));
rq->rq_disk = bd_disk;
rq->end_io = done;
/*
* don't check dying flag for MQ because the request won't
* be reused after dying flag is set
*/
if (q->mq_ops) {
blk_mq_sched_insert_request(rq, at_head, true, false, false);
return;
}
spin_lock_irq(q->queue_lock);
if (unlikely(blk_queue_dying(q))) {
rq->rq_flags |= RQF_QUIET;
__blk_end_request_all(rq, BLK_STS_IOERR);
spin_unlock_irq(q->queue_lock);
return;
}
__elv_add_request(q, rq, where);
__blk_run_queue(q);
spin_unlock_irq(q->queue_lock);
}
void __blk_run_queue(struct request_queue *q)
{
lockdep_assert_held(q->queue_lock);
WARN_ON_ONCE(q->mq_ops);
if (unlikely(blk_queue_stopped(q)))
return;
__blk_run_queue_uncond(q);
}
구현되어 있는 request_fn을 invoke한다. 여러 쓰레드가 이 request function을 concurrent하게 수행할 수 있음. -> lock 필요.
/**
* __blk_run_queue_uncond - run a queue whether or not it has been stopped
* @q: The queue to run
*
* Description:
* Invoke request handling on a queue if there are any pending requests.
* May be used to restart request handling after a request has completed.
* This variant runs the queue whether or not the queue has been
* stopped. Must be called with the queue lock held and interrupts
* disabled. See also @blk_run_queue.
*/
inline void __blk_run_queue_uncond(struct request_queue *q)
{
lockdep_assert_held(q->queue_lock);
WARN_ON_ONCE(q->mq_ops);
if (unlikely(blk_queue_dead(q)))
return;
/*
* Some request_fn implementations, e.g. scsi_request_fn(), unlock
* the queue lock internally. As a result multiple threads may be
* running such a request function concurrently. Keep track of the
* number of active request_fn invocations such that blk_drain_queue()
* can wait until all these request_fn calls have finished.
*/
q->request_fn_active++;
q->request_fn(q);
q->request_fn_active--;
}