Abstraction
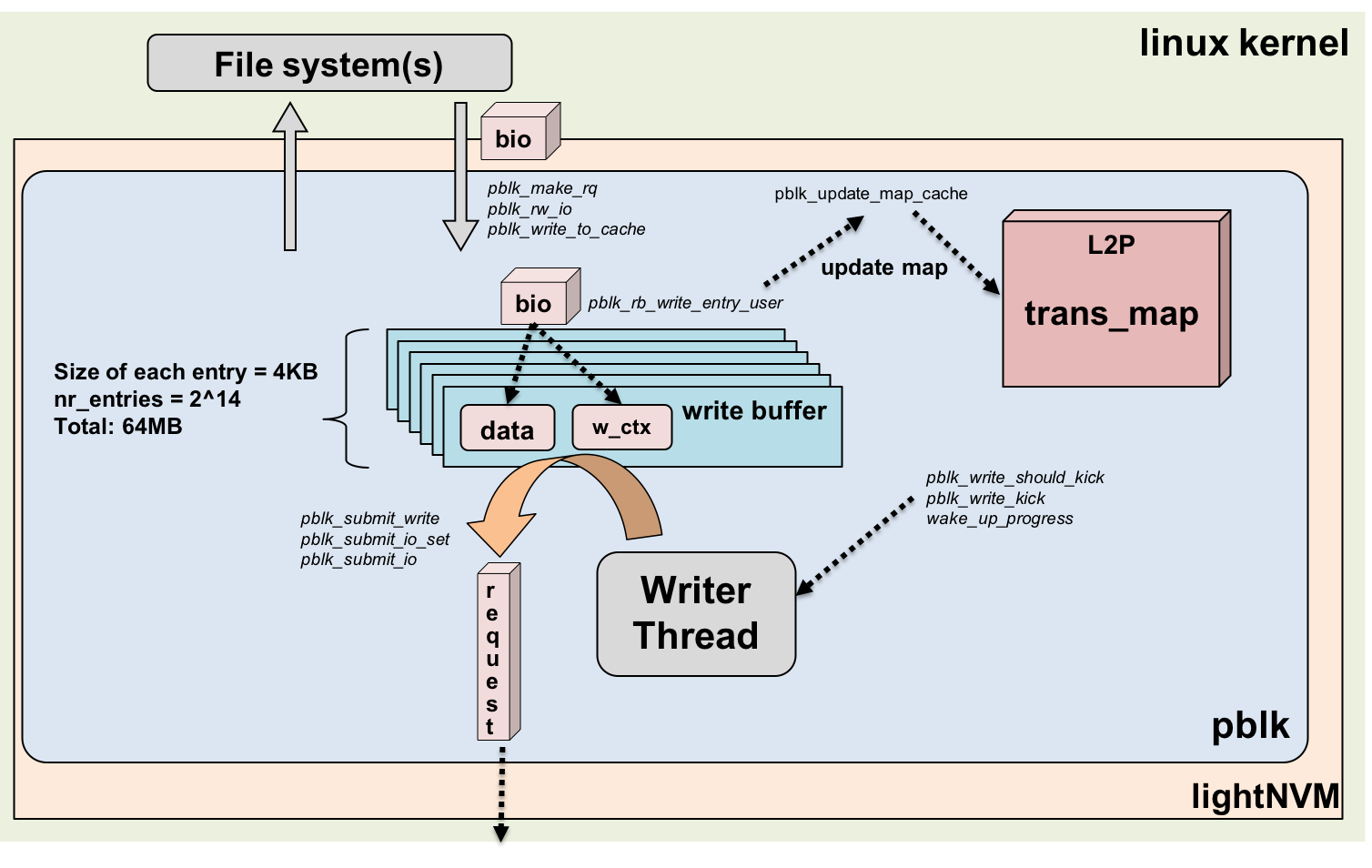
Open Channel SSD는 스토리지 디바이스에 FTL(Flash Translation Layer)을 구현하지 않고, 운영체제에 게 SSD(Solid-State Drive)의 관리를 맡기는 SSD이다. 따라서 리눅스에서는 LightNVM과 같은 추상화 계 층을 제공한다. pblk(The Physical Block Device)은 LightNVM Layer에 위치하는 커널 모듈로서 기존의 SSD의 FTL에서 수행하는 기능들을 호스트에서 수행한다. 본 논문에서는 Open Channel SSD에서 쓰기 요청의 처리 과정을 보이고, pblk에 구현되어 있는 소프트웨어 버퍼인 쓰기 버퍼(Write Buffer) 및 입출력 요청의 스레드 구성에 따른 성능 분석 결과를 보인다.
Introduction
향후 수년 내에 Solid-State Drive(SSD)는 지배적인 보조기억장치가 될 것으로 예상된다. SSD는 기존의 전통적인 Hard Disk Drive(HDD)에 비해서 우수한 성능을 보이지만, 스토리지 디바이스에 최적화 부족으로 인한 자원의 비효율 적인 이용 문제[4], long taillatency, unpredictable I/O latency와 같은 단점들을 갖는다 [1, 2, 3]. 이러한 문제점들은 대부분 Hard Disk Drive에 최적화 된 Block I/O 인터페이스 때문이다 [5].
Open Channel SSD는 위와 같은 문제점들을 해결할 수 있는 새로운 형태의 SSD 플랫폼이다. Open Channel SSD는 그 내부 Geometry를 호스트 운영체제에 드러내고, 호스트가 스토리지 디바이스 내부의 물리적인 데이터 배치나 I/O 스케줄링을 관리할 수 있게 한다. 이렇게 함으로서, 호스트와 SSD 컨트롤러는 SSD 디바이스 작동과 관련된 기능을 나누어 수행한다 [3]. 기존의 SSD의 FTL Layer에서 수행하던 address translation, garbage collection, error handling 과 같은 기능들이 호스트에서 수행될 수 있다. 따라서 시스템에 따라 스토리지 소프트웨어 스택을 Open Channel SSD를 사용하는 응용 프로그램에 알맞게 재 구성할 수 있다. 리눅스 커널 4.4 이후부터 호스트 기반의 SSD 관리 서브시스템인 LightNVM 계층이 사용되었고, 리눅스 커널 4.12 이후부터는 호스트에서 FLT(Flash Translation Layer)의 기능을 담당하는 pblk이 커널에 포함되었다. 이와 같은 시스템 상에서, Channel SSD는 하나의 물리적인 블록 디바이스로서 호스트에게 노출되어 보여지고, 사용자는 SSD를 특정 워크로드 패턴에 맞게 최적화 할 수 있다
Experimental setup and evaluation
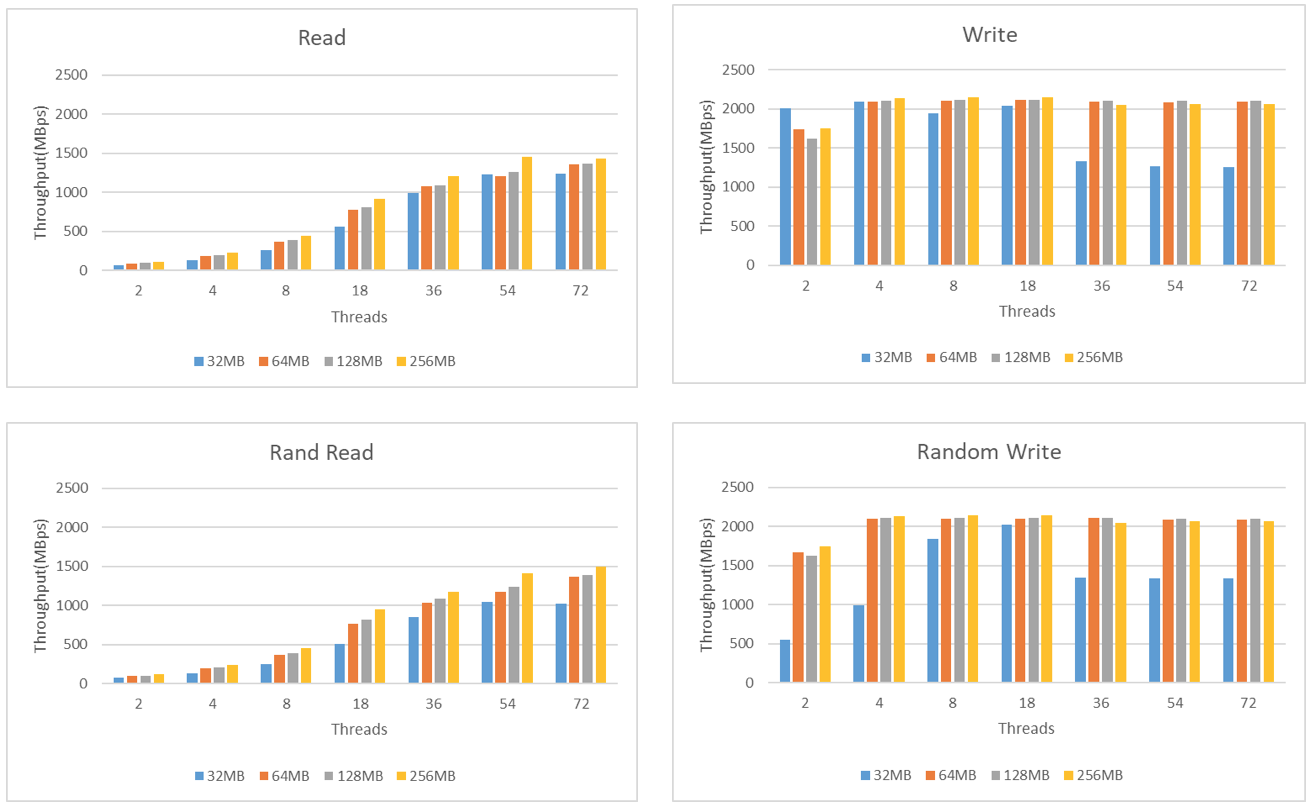
본 논문에서 보이는 실험의 목적은 두 가지 이다. 첫 번째로, LightNVM 스택의 pblk모듈에 구현된 쓰기 버퍼의 크기에 따른 입, 출력의 성능을 분석하는 것이다. 두 번째로, 병렬적인 입, 출력의 정도에 따른 성능 변화를 분석한다. 즉 여러 다중 코어, 다중 스레드 환경에서의 Open Channel SSD의 성능을 분석하는 것이다.
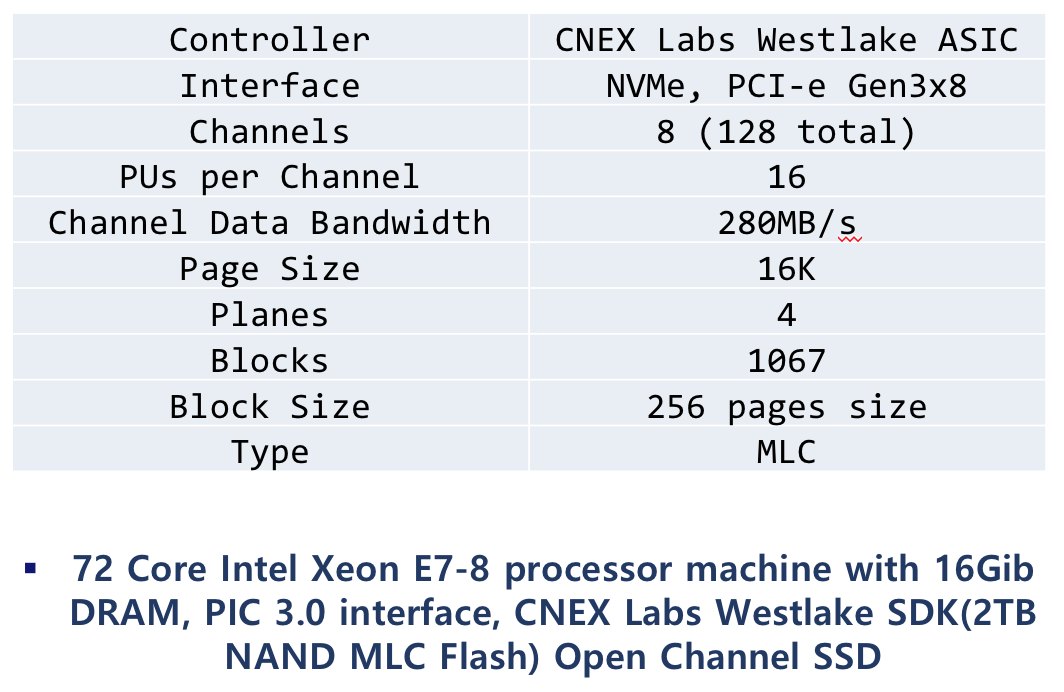
본 실험을 위해 72코어의 Intel Xeon E7-8870 프로세서 서버를 사용하였으며, 16Gib DRAM, PIC 3.0 인터페이스 및 CNEX Labs Westlake SDK(2TB NAND MLC Flash) Open Channel SSD를 사용하였다. Open Channel SSD의 상세한 특징은 <표 1>에 나타내었다. 호스트는 Ubuntu 16.04.3 LTS server를 사용하였고, pblk 모듈을 사용한 리눅스 커널 4.14.0-rc2 버전을 사용하였다. 디바이스의 입출력 성능 실험을 위해 fio[6]를 사용하였다. 실험은 파일시스템을 거치지 않고 디바이스에 직접 입출력 요청을 하도록 설정하였고, 동일한 실험 환경에서 3번의 실험을 진행한 뒤 평균값을 결과로 사용하였다. 입출력 스레드 수와 동일한 코어의 수만 활성화 시켜 실험을 진행하였으며, 쓰기 버퍼의 크기는 버퍼를 구성하는 엔트리의 개수를 조정하는 방식으로 시스템을 구현하였다.
Conclusion
실험 결과에 따르면 Open Channel SSD 읽기 요청 처리 성능은 스레드 수에 비례하여 점점 증가하다 어느 정도 병렬성의 정도가 증가하면 성능의 증가율이 감소하는 모습을 보인다. 특히, 읽기 요청 스레드가 54개에서 72개로 증가할 땐 성능의 변화가 거의 없었다.
쓰기 버퍼의 크기에 따른 성능은 스레드 개수에 상관 없이 모두 일정한 증가 비율을 나타냈는데, 이는 쓰기 버퍼의 크기가 증가함에 따라, 읽기 요청 시 버퍼 캐시 히트 비율이 증가했기 때문이다.
64MB이상의 버퍼 크기에서 진행한 쓰기 요청에 대한 성능 실험결과는 스레드가 2개에서 4개로 증가할 때, 약간의 증가율을 보이지만 나머지 구간에서는 큰 증가율을 보이지 않는다. 쓰기 버퍼의 크기가 32MB일 때에는 임의 쓰기 요청(random write request)시 스레드의 수에 따라 18개 스레드 수 까지는 비교적 큰 비율로 쓰기 성능이 증가한다.
쓰기 버퍼의 크기가 32MB일 때, 일반 쓰기와 임의쓰기 모두 18쓰레드 이후 쓰기 성능이 18개의 스레드 일 때와 비교하여 큰 폭으로 감소함을 보인다. 이는 작은 크기의 버퍼에 비해 많은 쓰기 스레드가 쓰기 요청을 하여, 항상 버퍼가 가득 차있는 상황을 나타내고, 더 이상 성능의 증가가 나타나지 않음을 나타내는 것으로 예상된다.
실험 결과를 통해 쓰기 버퍼의 크기 및 스레드 구성에 따른 입출력 요청의 성능 양상을 확인할 수 있었다. 특히 읽기 요청에 비해 쓰기 요청은 스레드 수 및 쓰기 버퍼가 증가해도 성능의 향상이 크지 않음을 확인하였다. 차후 진행될 연구에서는 이러한 쓰기 요청에서의 성능 증가를 막는 원인을 파악하고, 병렬성을 높이는 것을 포함한다.
Reference
[1] Hao, M., Soundararajan, G., Kencham mana Hosekote, D. R., Chien, A. A., & Gunawi, H. S. (2016, February). The Tail at Store: A Revelation from Millions of Hours of Disk and SSD Deployments. In FAST (pp. 263-276).
[2] Chen, F., Luo, T., & Zhang, X. (2011, February). CAFTL: A Content-Aware Flash Translation Layer Enhancing the Lifespan of Flash Memory based Solid State Drives. In FAST (Vol. 11, pp. 77-90).
[3] Bjørling, M., González, J., & Bonnet, P. (2017, February). LightNVM: The Linux OpenChannel SSD Subsystem. In FAST (pp. 359374).
[4] Agrawal, N., Prabhakaran, V., Wobber, T., Davis, J. D., Manasse, M. S., & Panigrahy, R. (2008, June). Design Tradeoffs for SSD Performance. In USENIX Annual Technical Conference (Vol. 8, pp. 57-70).
[5] Swanson, S., & Caulfield, A. M. (2013). Refactor, reduce, recycle: Restructuring the i/o stack for the future of storage. Computer, 46(8), 52-59.
[6] AXBOE, J. Fio - Flexible I/O tester. URL http://freecode.com/projects/fio (2014).